מה הם מחסני נתונים (Data Warehouse) וכיצד מנהלים אותם?
מחסן נתונים DWH- Data Warehouse מבוסס על מערכת ממוחשבת, אשר משמשת כמאגר נתונים ארגוניים רחב היקף, לרבות נתונים רב-תקופתיים והיסטוריים, נתונים על תנועות כספיות, שינויים במצבת המלאי, פעולות שיווק מול לקוחות, מעקב אחר שירות הלקוחות, מכירות, הזמנות רכש, ייצור ומשאבי אנוש. ארגונים נעזרים במחסני נתונים כדי לנתח מידע ולבצע השוואות בין-תקופתיות לצורך החלטות עסקיות, ולכן מחסני נתונים משמשים גם כמערכות תומכות החלטה, שכן הם מהווים את התשתית המרכזית למערכות הבינה העסקית (BI) .
[toc]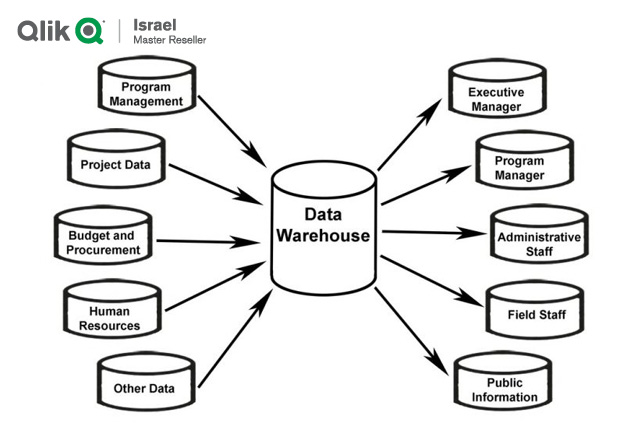
ניהול מחסני נתונים
תהליך ארגון המידע במחסן הנתונים כולל שלושה שלבים עיקריים:
- הנתונים מוזרמים אל המחסן ישירות ממערכות המידע התפעוליות של הארגון לרבות מערכת לניהול משאבי הארגון (סאפ, פריוריטי, חשבשבת, ERP) מערכת לניהול קשרי לקוחות (CRM), ניהול רצפת ייצור (MES), ניהול מחסן בזמן אמת (WMS) מערכות לניהול משאבי אנוש וכל מערכת תפעולית אחרת שמשמשת את הארגון.
- הנתונים מסוננים וממוינים (עוברים תהליך של "טיוב") בהתאם לפקודות שונות במטרה למזער "רעשי רקע" ולהתאים להקשר הנכון (הנתונים יישלפו באמצעות שאילתה או שאלה עסקית, תלוי בפלטפורמת ה-BI)
- הפיכת נתונים גולמיים לתובנות עסקיות בעזרת תהליך ניתוח נתונים.
<<< צרו איתנו קשר לעוד מידע על המערכות של Qlik לניהול מחסני נתונים >>>
מדוע צריך מחסני נתונים?
מלבד הצורך בריכוז, אחזור, סינון, מיון והפיכת נתונים גולמיים לתובנות עסקיות, ארגונים נעזרים במחסני נתונים לצורך חיבור בין מערכות שונות ואחזור מהיר של מידע גם כאשר הנתונים אינם נגישים (נמצאים במערכות סגורות) . כמו כן בשונה ממערכות תפעוליות – המצריכות ניהול של מספר טבלאות סביב אותה ישות במחסן הנתונים, מבוצע תהליך "טיוב" אוטומטי של נתונים, דבר החוסך בנפח אחסון ובזמן ריצה – למשל: כאשר תאריך הלידה נרשם בהפרדה של פסיקים לעומת תאריך לידה שנרשם בהפרדת לוכסנים או תעודת זהות שנרשמה עם או ללא ספרת ביקורת.
נוסף לכך המערכות התפעוליות הארגוניות אינן מתוכננות לשמור נתונים היסטוריים לאורך זמן, כך שבמקרה הטוב ניתן לגשת לנתון שנרשם בטווח של שבועות ספורים, ומה שהיה קודם לכן לא נשמר. בשונה מכך ארגונים שמעוניינים לבצע ניתוחים סטטיסטיים המתפרסים על פני ציר זמן של שנים רבות (לדוגמה כמות מפריט מסוים שנמכרה במשך עשור) יכולים לעשות זאת באמצעות שימוש במחסן נתונים – מערכת שנוצרה מראש כדי לאחסן אינספור נתונים ומאופיינת בנפח אחסון רחב ושיטת אחסון המבוססת על שכבות (רובד על רובד). באופן זה ניתן לשלוף נתונים במהירות ואף לאחזר מידע בנוחות ובקלות, כולל אחזור מידע ממערכות לא פתוחות כדוגמת MF (וזאת כיוון שבמחסן הנתונים אין כפילות של טבלאות, ולכן אין כל חשש להאטת הקצב או להצגת שגיאות בעת ריצת הנתונים.
מערכות מחסני נתונים
מחסן הנתונים מורכב בעצם משתי שכבות: מערכת רב-ענפית (ארגונית, Data Warehouse) ומערכת ענפית (מחלקית, Data Mart), כאשר בשכבה הראשונה מחסן הנתונים נותן מענה למספר מחלקות ומציג את הנתונים בהקשר של שאלה עסקית מובחנת התואמת את עולמו המקצועי של המשתמש, ואילו בשכבה השנייה המחסן מיועד לתחום עסקי מובחן – כספים, רכש, מלאי, משאבי אנוש וכן הלאה. השיקול אם לבנות מחסן נתונים בשכבה רב ענפית לעומת בניית מחסן נתונים ענפי אחד מבוסס על משאבים שונים לרבות תקציבים וזמן – שכן בנייה של מחסן נתונים איכותי הוא פרויקט מתמשך.
מערכת רב-ענפית (ארגונית, Data Warehouse)
מחסן נתונים שנותן מענה למספר תחומים עסקיים ומרכז נתונים המשותפים לתחומים שונים – לדוגמה: טבלת לקוחות, טבלת מכירות, טבלת הזמנות רכש וכן הלאה. בתהליך הקמת המחסן יש לשים דגש כיצד כל טבלה נותנת מענה לצרכים הייחודיים של הענפים השונים בארגון ולצרכים הרבים של משתמשי המערכת. המערכת מתאימה לארגונים בסדר גודל בינוני ומעלה המנהלים מספר מערכות מידע לרבות מערכת ERP, CRM, ייצור, משאבי אנוש ועוד מערכות נוספות, ונדרשים לתת מענה למספר עולמות תוכן.
מערכת ענפית (מחלקית, Data Mart)
מערכת ענפית מחלקתית כוללת מחסן נתונים הממוקד לתחום עסקי מובחן – למשל מחסן נתוני כח אדם, מחסן נתוני שכר וכן הלאה. זהו למעשה מחסן נתונים פנימי, והוא פועל בדרך כלל לצד מחסני נתונים ענפיים מקבילים – כאשר כל מחסן ענפי מאחסן את המידע המחלקתי הייעודי. בארגונים הבוחרים בגישה של ביזור ניתן לראות מספר מחסני Data Mart.
כיצד בנויה מערכת מחסן נתונים קלאסית?
מערכת תפעולית
נקראת גם מאגר נתונים תפעולי OLTP (On Line Transactional Processing) ומטרתה לאגור ולנהל נתונים בתדירות יום יומית בהתאם לשיוכה במערכת. לדוגמה: שינויים שחלו בכרטיסיית לקוח, שינויים שחלו בפרטי מוצר מסוים (לדוגמה: היסטוריית הנחות, בעיות עם לוטים ועוד) כאמור המאגר מתעדכן בתדירות יום יומית ומשמש לניהול תנועות לישות במערכת וצפייה בתנועות היסטוריות.
מאגר נתונים תפעולי
מאגר נתונים תפעולי, ODS (Operational Data Store) משמש כמסד לנתונים עדכניים, אשר מספק "תמונת מצב" ואפשרות למעקב אחר התנועות האחרונות שבוצעו בארגון בכל תחום. נוסף לכך הוא מאפשר לארגונים לאחד נתונים שמקורם בתבניות שונות וכך להקל על אופן קריאת הנתונים וניתוחם.
קליטה וטיפול בנתונים
תהליך קליטה וטיפול בנתונים Staging Area) – STA) נעשה באזור "העמסת ביניים" או "אחסון ביניים" המאפשר לעבד נתונים בתהליך ETL (הוצאת נתונים מקובצי מקור, שינוי מבנה הנתונים וסיכומם וטעינת נתונים למחסן נתונים). מיקומו של אזור זה נמצא בין מאגרי ידע שונים לרבות מחסני נתונים ענפיים ומחסני נתונים רב-ענפיות ומאגרים נוספים.
מאגר המידע
ה- Data Warehouse בסיס הנתונים העיקרי של מחסן נתונים. בבסיס זה מאוגדים כלל הנתונים שנגזרו מהמערכות התפעוליות לאחר שעברו "טיוב" והתאמה להצגתם בתבנית אחידה המקלה על ניתוח, אחזור ושליפת המידע. מחסן הנתונים משמש לבינה עסקית, כריית מידע ומתן מענה לשאילתות רב-מימדיות (עיבוד אנליטי מקוון).
ממשק משתמש
זהו כלי גרפי המשמש את משתמש הקצה לחקור נתונים, להפיק שאילתות, לחולל דוחות ולבצע שימוש מעשי במערכת הבינה העסקית העומדת לרשותו. ממשק משתמש איכותי כולל אינספור מוטיבים גרפיים שונים אשר מקלים על קריאה וניתוח הנתונים, ואף מאפשרים לבצע תחקור חופשי של הדאטה על גבי הדשבורד (יכולת שקיימת רק במערכות BI מהדור החדש).
<<< צרו איתנו קשר לעוד מידע על המערכות המתקדמות של Qlik לניהול מחסני נתונים >>>
מה ההבדל בין מבנה מחסן נתונים למערכות עיבוד נתונים
עסקים המתמודדים עם ניתוח של אינספור נתונים יום יומיים, ומבקשים להשוות ביצועים עסקיים בין תקופות שונות נדרשים הן למחסן נתונים והן למערכות לעיבוד נתונים – שתי מערכות שיעודן המרכזי הוא לאחסן נתונים, אולם הן נוצרו למטרות שונות, ולכן הן נבדלות זו מזו במספר מאפיינים:
- תהליך עיבוד: OLAP מול OLTP – ההבדל העיקרי בין מחסן נתונים למערכות עיבוד נתונים הוא באופן עיבוד הנתונים. במחסן נתונים נהוג להיעזר בתהליך עיבוד תנועות מקוון (OLTP) כדי למחוק, להוסיף, להחליף או לעדכן מספר רב של רשומות מקוונות בזמן קצר ואילו במערכות עיבוד נתונים, המיקוד בתהליך העיבוד נעשה במסות רבות יותר של נתונים כדי לאפשר למשתמש לנתח את המידע ממגוון נקודות מבט וזוויות. זהו תהליך מהיר יותר ומאפשר לשלוף את הנתון בהקשר הנכון.
- אופטימיזציה – במערכות עיבוד נתונים ניתוח הדאטה נעשה ברמת "המיקרו", כלומר ברמת רישום התנועה, לעומת זאת במחסני נתונים – הניתוח נעשה ברמת "המאקרו" ונותן מענה לשאילתות מורכבות אשר מבוססות על מאגרי נתונים רב-ממדיים וגדולים.
- ניתוח מידע – במערכות לעיבוד נתונים המיקוד הוא על תהליך העיבוד עצמו, ניתן אף לבצע ניתוח נתונים ברמה בסיסית או ברמה מורכבת ביותר אך במקרה זה נדרשת התערבות של איש פיתוח כדי שיחבר בין מספר טבלאות וייתן מענה לשאילתות מורכבות. ברוב המקרים גם לאחר תהליך זה הניתוח המתקדם יניב דו"ח סטטי, שאינו מאפשר להגיע לתובנות מעמיקות. לעומת זאת מחסני נתונים נוצרו כדי לתת מענה לניתוחים מורכבים, רב-ממדים, ולחקירה "חופשית" של הדאטה על גבי מסך העבודה, ללא תלות בצוותי פיתוח או בשאילתות מובנות מראש. בדרך זו ניתן להגיע לתובנות מעמיקות ולא רק "לקרוא" נתונים מתוך דו"ח סטטי.
- תמיכה במספר משתמשים במקביל – מערכות לעיבוד נתונים נותנות מענה למספר רב של משתמשים במקביל, לעומת זאת מחסני נתונים מיועדים למספר קטן של משתמשים במקביל
- הצגת מידע עדכני – מערכות לעיבוד נתונים עובדות "בזמן אמת" ולכן מציגות נתונים עדכניים, בשונה מהן מחסני נתונים הם מאגרים לאחסון נתונים, ולכן מוצגים בהם נתונים היסטוריים הנוגעים לתחומים שונים בארגון.
כיצד מעצבים בסיס נתונים למערכת של מחסן נתונים
בסיס נתונים המשמש למערכת של מחסן נתונים נדרש לתת מענה לשני אתגרים מרכזיים ביג דאטה ויכולת להפיק שאילתות מורכבות:
ביג דאטה – והכוונה לצבר נתונים שמגיעים מאינספור מקורות ומעובדים על ידי מנוע רב עוצמה שפועל בבסיס המערכת.
הפקת שאילתות מורכבות – מתבטאת ביכולת לתחקר את הדאטה בחופשיות, ללא תלות בשאילתות, כאשר המידע מגיע מטבלאות בהן הנתונים משוכפלים מספר פעמים (בשונה מטבלאות מנורמלות שממזערות ככל הניתן כפילות בין נתונים בטבלה אחת) ,וכן לא פעם מוצגים נתונים מסוכמים כדי לתת מענה לצורך בצפייה במידע רב-שכבתי. שמירה על עקרונות עיצוב אלו ישפר באופן משמעותי את חווית המשתמש ואת ביצועי המערכת לאורך זמן.
מודל כוכב
זהו העיצוב הקלאסי למחסן הנתונים, והוא מבוסס על טבלת סיכום המרכזת את רשומות המידע הגולמיות, שמסביבן ממוקמות טבלאות המגדירות חתכים שונים של דאטה וטבלאות סיכום במטרה לתת מענה לשאילתות מורכבות. למודל הכוכב יש יתרונות וחסרונות – מחד מדובר במודל פשוט יחסית, שמקטין את הצורך באיחוד שדות בין שתי טבלאות על סמך ערכים משותפים, משפט מודלים מורכבים, משמש גם כמקור נתונים לבסיס נתונים רב-ממדי אשר נותן מענה לשאילתות מורכבות, ומאידך כדי לתת מענה לאותה מורכבות שנדרשת ברמת הניתוח הוא משכפל נתונים ולכן צורך שטחי אחסון נרחבים. כמו כן כפועל יוצא מפעולת השכפול, תתכן אפשרות להיעדר עקביות וכן שימוש בטבלאות סיכום רבות.
מודלים נוספים לניהול מחסני נתונים
סכמת פתיתי שלג
דומה בצורתה לסכמת הכוכב אך מבוססת על ממדים המנורמלים למספר טבלאות המקושרות ביניהן, ולכן מאופיינת ברמת סיעוף גבוהה הנוצרת כתוצאה מריבוי רמות קשר בין נתונים שונים. הסכמה משמשת בעיקר מחסני נתונים רב-ממדים ומערכות ענפיות לשליפה מהירה של נתונים, נהוג לבחור עיצוב סכמת פתיתי שלג, כאשר נדרש להפיק שאילתות מורכבות.
סכמת גלקסיה
נקראת גם סכמה מרובת כוכבים או סכמת מרובה כוכב, ומשמשת אף היא לניתוחים מורכבים רב-ממדיים הדורשים יותר משאילתת SQL אחת וכוללת שתי טבלאות נתונים החולקות טבלאות ממדים. נהוג לבצע בה שימוש בשאילתות מורכבות מאוד, כיוון שהיא מקשרת בין מספר מערכות של מחסני נתונים, שחולקות טבלאות ממדי נתונים משותפות.
מדוע מערכת ה-BI של Qlik עדיפה לניהול מחסני נתונים
Qlik מבוססת על טכנולוגיית זיכרון ליצירת קבצים פנימיים, אשר מתפקדים כמחסן נתונים רגיל דמוי מסד נתונים. זהו פתרון "היברידי" המשמש הן לאחסון נתונים והן ככלי לדיווח גמיש. כאשר בבסיס המערכת פועל מנוע אסוציאטיבי (פטנט רשום) אשר מעבד מידע ומציג אותו בהקשר הנכון גם אם לא חשבת לתחקר לגביו, ובחזית המערכת ישנו יישום אינטרנטי (דשבורדים) שמשמשת כסביבה לחקירת וניתוח דאטה במספר רמות ורבדים, ללא הגבלת שאילתה, וללא תלות באנשי פיתוח. הפלטפורמה של Qlik מתממשקת לאינספור מקורות פנים ארגוניים (גיליונות אקסל אלקטרוניים, תיקיות, קובצים) ואינספור מקורות חיצוניים (פורטלים, תיבות דואר, אתרי אינטרנט, רשתות חברתיות), כך שכל המידע מאוחסן במקום אחד ונגיש למשתמשי הארגון בהתאם להגדרות התפקיד ולרמת האבטחה שלהם. נוסף על כך חקירת הדאטה מתאפשרת בכל כיוון שבו יבחר המשתמש על ידי הקלדת ערך אקראי או על ידי הקלדה של שאלה גם אם מדובר בשאלה מורכבת ביותר – אשר מצריכה שימוש במספר טבלאות המגיעות ממספר מאגרי נתונים. בדרך זו הפלטפורמה מאפשרת לחקור דאטה במספר "שכבות ידע" ולהתמודד גם עם מודלים מורכבים ביותר ועם מאגרי מידע מרובים מאוד, כדוגמת מודל הגלקסיה.
